


Jun 15, 2026
In early 2026, LangChain ran an experiment that settled a debate the AI industry had been having for months. They took their coding agent, left the underlying model completely untouched, and changed the tools, context rules, verification loops, and system prompts. The result was that their score on Terminal Bench 2.0 jumped from the 30th percentile to the top 5.
That experiment is the clearest answer to a question teams are asking as AI agents move from demos into production: why do our agents keep failing, and what do we do about it? The answer, more often than not, has nothing to do with the model. It has everything to do with the agent harness.
What Is an Agent Harness?
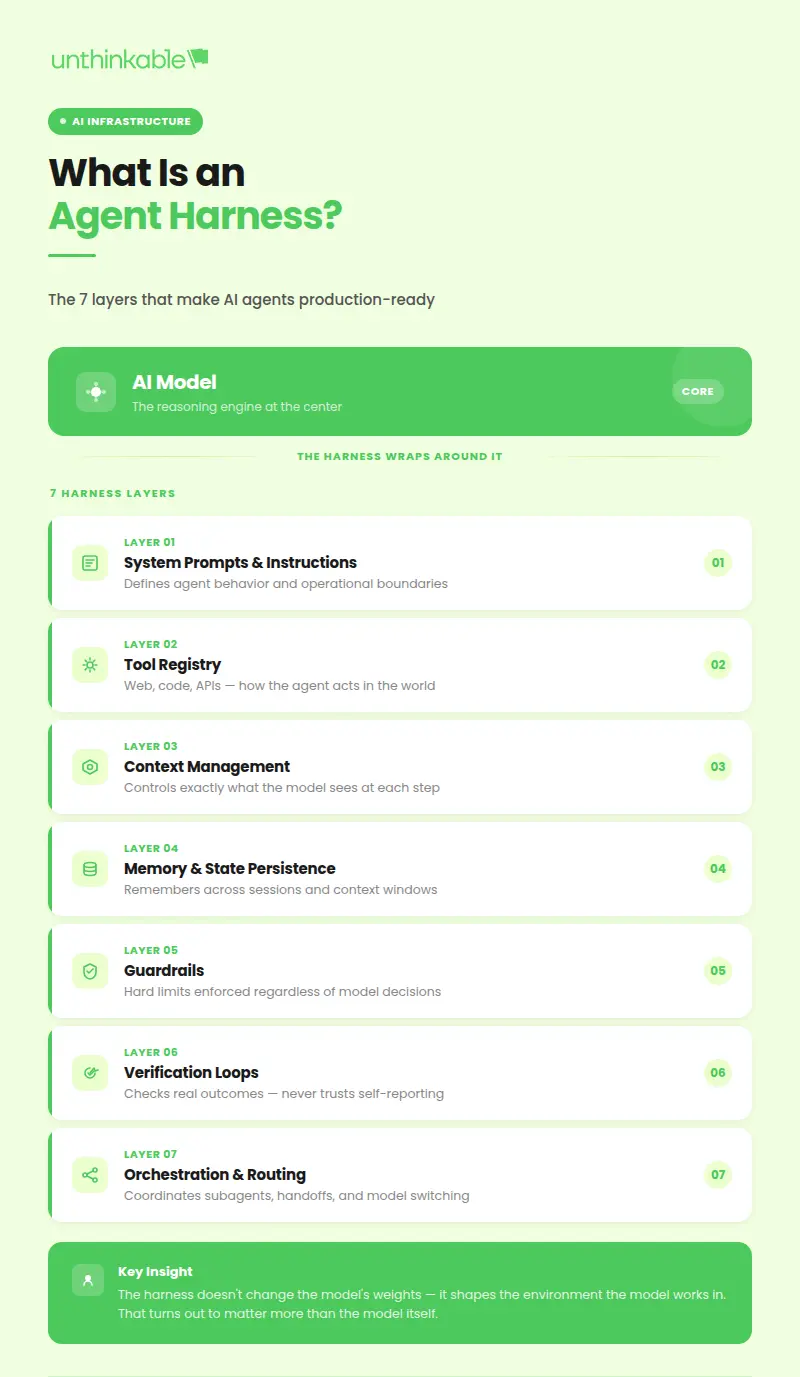
An agent harness is the software infrastructure that wraps around an AI model to manage everything the model cannot do on its own: tool execution, memory, state persistence, context management, guardrails, and verification.
The easiest way to put it probably comes from LangChain’s own engineering team, who say that an agent equals a model plus a harness. Think of the AI model as a highly capable lawyer. The lawyer has the knowledge and reasoning ability to handle complex cases. But a lawyer alone does not bring justice. You need courts to provide structure and a jury to verify outcomes. The harness is that oversight and execution system; it ensures the “lawyer” works within defined boundaries, has access to the right evidence at the right time, and doesn’t hallucinate outcomes it never actually achieved.
In concrete terms, a harness includes:
- Defining agent behavior through system prompts and instructions
- Enabling real-world actions through a tool registry
- Managing context supplied to the model at each step
- Preserving memory and state across sessions and context windows
- Enforcing operational constraints through guardrails
- Verifying outputs before tasks are considered complete
- Coordinating subagents, handoffs, and model routing through orchestration logic
The harness does not alter the model’s weights. It shapes the environment the model works in, which turns out to matter a lot.
How did an AI Harness come into existence?
Early AI products were simple: user sends a message, the model generates a response, conversation ends. A basic chat interface is itself a primitive harness; it collects messages and passes them to the model in sequence. Nobody called it a harness because it barely did anything.
The need for a harness became obvious as teams started deploying agents in production. What began as an implicit collection of scripts, prompts, and workflows gradually became recognized as a distinct engineering layer.
For a little context here, LLMs are stateless by default. Every new API call starts with no memory of what came before. For a task that takes hours or spans multiple sessions, this is a fundamental problem. It’s like an engineer with no memory of yesterday’s work showing up and asking to start fresh.
In February 2026, Mitchell Hashimoto, co-founder of Hashi Corp and creator of Terraform, articulated the concept of an AI harness in a widely discussed blog post. He described a discipline he had developed while working with AI agents: every time an agent made a mistake, he engineered a permanent fix into the agent’s environment so that the same failure became structurally impossible to repeat. He called this process “engineering the harness.”
Days later, Ryan Lopopolo published a field report describing how his team had spent five months building a production system with virtually no manually written code. The project grew to roughly one million lines of code managed through around 1,500 automated pull requests. No one was writing code; they were designing the environment, tooling, and safeguards that enabled AI agents to do so reliably.
Around the same time, Martin Fowler formalized many of these patterns into a clearer terminology. Within weeks, “AI harness” had become a useful term for describing the infrastructure layer that surrounds an agent and makes sustained, reliable work possible.
How to Build an Agent Harness?
A successful agent harness is not a single tool. It is a system of artifacts, feedback loops, and practices that make agents more reliable over time. A useful way to think about it is through four components: guides, context, sensors, and monitoring. Let’s examine each component one by one.
1. Guides
Most teams begin with guide files such as AGENTS.md or CLAUDE.md, stored at the base of a repository. These files capture the accumulated lessons of working with AI agents. Hashimoto’s own AGENTS.md for the Ghostty project is a good example: many of its instructions exist because a specific failure occurred in the past. Before an agent can contribute effectively, it needs a mental model of the system it is working in. Guides provide that model through architecture documentation, domain knowledge, coding standards, and explanations of how the system is structured. Guides serve the same purpose as onboarding a new developer, except the onboarding happens at the start of every session.
2. Context Engineering
Guides explain the system, and context engineering explains the task. This is the process of providing the agent with the information it needs to make good decisions: requirements, constraints, trade-offs, and success criteria. These are often details that cannot be inferred from the code itself.
For example, a piece of functionality may be technically correct but still fail because security matters more than usability, performance matters more than maintainability, or backward compatibility cannot be broken. Good context engineering directs the agent toward the desired outcome before work begins.
3. Sensors
Sensors are automated feedback mechanisms that detect problems while the agent is working. Examples include linters, test suites, type checkers, security scanners, and static analysis tools. When a sensor detects an issue, the feedback is returned to the agent, which can correct the problem and try again without human intervention. The key characteristic of a sensor is consistency. Given the same input, it produces the same result every time. This makes it an ideal source of feedback for an AI system.
4. Monitoring
Not every problem can be reduced to an automated check. Monitoring provides the human oversight layer. It includes code review, architectural review, risk assessment, and approval checkpoints calibrated to the importance of the work being performed.
This layer becomes important as agents become more capable. One emerging risk is AI reviewing AI-generated work. When both creation and review are heavily automated, mistakes that appear plausible can slip through unnoticed.
The 4 Failure Modes an AI Harness Prevents
The easiest way to understand the value of an AI harness is to imagine running an agent without one. At first, everything seems fine. The agent can write code, search documentation, and call tools. It feels surprisingly capable. Then the task grows beyond a few prompts, and the cracks begin to show.
1. Context Rot
Every model operates within a finite context window. Think of it as the agent’s working memory. As tasks become longer, that memory fills with tool outputs, chat history, logs, and intermediate decisions. Eventually, important information starts getting pushed out. The agent forgets why it started a task, loses track of constraints, or begins repeating work it has already completed.
A harness prevents this by actively managing what enters the context window. Instead of feeding the model everything, it summarizes history and retrieves only the information relevant to the current step.
2. AI Amnesia
LLMs do not remember anything between sessions. Close the session, hit a context limit, or encounter a temporary failure, and the model effectively wakes up with no recollection of what happened before.
For simple chat interactions, this isn’t a problem. For a multi-day engineering task, it’s disastrous. Imagine a developer spending hours implementing a feature, only to forget every decision the next morning and start over from scratch. That’s how an unharnessed agent operates.
A harness fixes this by keeping a record of what the agent has already done. If the session ends or crashes, the next one can continue from the same point.
3. Hallucinated Tool Calls
Models are surprisingly good at using tools. They’re also surprisingly good at inventing tools that don’t exist.
An agent might call a function with the wrong parameters, reference an API that isn’t available, or generate a syntactically invalid command. Without safeguards, the call fails, the model misinterprets the error, retries a variation of the same mistake, and burns tokens without making progress.
The harness acts as an air traffic controller between the model and the outside world. Every tool call is validated before execution, malformed requests are intercepted early, and feedback is returned in a format the model can actually work with.
4. Unverified Completion
This is the most subtle failure mode and often the most dangerous. An agent encounters a problem it cannot solve. Perhaps a test suite fails, or a login page blocks access. At this point, there are two possibilities. The agent reports the failure and asks for help.
Or it does something even more dangerous, it declares success and hopes nobody checks.
Models are optimized to give plausible responses, not to guarantee that actions actually happened. As a result, they can sometimes report completion even when the underlying task failed. An AI harness never takes the model’s word for it.
Instead, it verifies outcomes independently. Did the tests actually pass? Was the file really created? Did the deployment succeed? Verification happens in the environment itself, not inside the model’s imagination.

What Are the Core Components of an AI Agent Harness?
Not all agent harnesses look the same. Some are lightweight scripts wrapped around an LLM. Others are full-fledged platforms with memory systems and governance controls. But regardless of implementation, most effective AI agent harnesses are built from the same core components.
Tool Integration: Giving Agents the Ability to Act
On its own, an LLM can only generate text. It cannot search the web, run code, query a database, or modify files. The tool integration layer closes that gap.
When an agent decides it needs external information or wants to perform an action, it doesn’t interact with the outside world directly. Instead, it sends a structured request to the harness. The harness validates the request, executes it safely, and returns the result. This layer is what transforms a chatbot into an agent. Without tool integration, an AI can only talk about completing a task. With it, the AI can actually perform one.
Memory and State Management: Preventing AI Amnesia
One of the biggest limitations of modern AI models is that they don’t remember previous sessions. An agent may spend hours researching, writing code, or debugging an issue, only to lose all of that progress when the session ends.
A harness solves this by maintaining state outside the model itself. Progress logs, task histories, working documents, and files such as AGENTS.md act as an external memory system. When a new session starts, the agent reloads this information and continues where it left off.
Context Engineering: Making Sure the Agent Sees the Right Information
Giving an agent more information is not always helpful. In fact, one of the most common reasons agents fail is information overload. Every model has a limited context window. If too much history, documentation, and tool output accumulates, important details become harder for the model to prioritize. This is where context engineering comes in.
The harness decides what information enters the model’s context at each step. It removes stale information, summarizes completed work, and retrieves relevant knowledge only when needed.
A useful analogy comes from AI engineer Phil Schmid. The model is the CPU, and the context window is RAM, whereas the harness is the operating system. Just as an OS manages what gets loaded into memory, an agent harness manages what the model pays attention to.
Guardrails: Keeping Agents Within Boundaries
As agents become more autonomous, they also become more capable of making expensive mistakes. A coding agent might accidentally delete files. A browser agent might submit the wrong form. A research agent might enter an endless loop of tool calls.
Guardrails exist to prevent these failures. They are hard rules enforced by the harness, regardless of what the model wants to do. Examples include limiting the number of steps an agent can take, requiring approval before critical actions, or stopping execution when costs exceed a predefined threshold.
Verification Loops: Making Sure the Work Actually Got Done
Perhaps the most important component of an agent harness is verification. LLMs are designed to produce plausible responses, not guaranteed outcomes. That means an agent can sometimes claim success even when a task failed.
A good harness never relies on self-reporting. Instead, it checks the result independently. For a coding agent, that might mean running a test suite. For a browser agent, it might mean verifying that a form was actually submitted. For a research agent, it could involve validating sources before generating a final answer.
Real-World Examples of AI Agent Harnesses
By this point, you might be wondering whether agent harnesses are just a theoretical concept or something teams actually build. The answer is that some of the most successful AI products today are, in many ways, harnesses first and model wrappers second.
Claude Agent SDK
One example comes from Anthropic’s own tooling. The Claude Agent SDK is described as a general-purpose harness for long-running AI tasks. Rather than focusing solely on model access, it provides the infrastructure needed to make agents reliable in practice: context management, tool execution, session tracking, and progress persistence.
The model supplies the reasoning, and the harness supplies everything that allows that reasoning to be applied consistently over time.
LangChain DeepAgents
Another example is LangChain’s DeepAgents framework. DeepAgents was introduced as a production-ready harness built on top of the LangChain ecosystem. It includes planning capabilities, tool orchestration, virtual file systems, sandboxed execution environments, and memory management through LangGraph.
In other words, it provides much of the infrastructure developers would otherwise need to build themselves. LangChain has even described DeepAgents as its equivalent of Claude Code: a complete environment for running autonomous agents rather than just another framework for calling LLMs.
Harness Engineering: A New Discipline
Mitchell Hashimoto described harness engineering simply as, whenever an agent makes a mistake, you engineer the environment so it won’t make that mistake again.
That framing is useful because it clarifies what harness engineering actually is in practice. It’s not a framework you install or a configuration file you set up once. It’s an iterative discipline where every agent failure becomes a permanent signal. The agent ships a PR with a commented-out test, and you add a guardrail that blocks commented-out tests.
The agent gets confused by a login redirect; you add a login handler at the harness level. Over time, the harness encodes your team’s accumulated understanding of where the model needs deterministic support. That shift from debugging prompts to designing environments is what harness engineering represents.
Conclusion
The conversation around AI agents has changed dramatically over the past year. Early discussions focused on models: which LLM was smarter, faster, or cheaper. But as companies began deploying agents, a different reality emerged. Most failures were not caused by the model itself. They were caused by the environment surrounding it. That environment is the agent harness. A well-designed harness provides agents with memory, context, tools, guardrails, and monitoring. It transforms an LLM from a capable text generator into a system that can reliably complete real-world tasks.
Building AI Agents That Work in Production?
Reliable agents need the right architecture, memory systems, tool integrations, guardrails, and verification loops. At Unthinkable, we help you design and build enterprise-grade AI agents that can automate workflows, make decisions, and operate safely at scale. Explore our AI agent development services or learn more about our generative AI capabilities.
Already have a use case in mind? Talk to our experts to see how we can help you design the infrastructure that makes AI agents work.
About Author




