Business Situation
IndiaAI’s motive was to consolidate fragmented datasets across ministries, universities, hospitals, and private organizations and develop a data repository to train AI models. Data engineers spent hours sourcing, cleaning, and validating information from multiple sources. Private datasets were costly, inconsistent, and lacked standardized licensing frameworks. Limited access to GPUs further slowed AI model training, making development expensive, time-consuming, and unreliable.
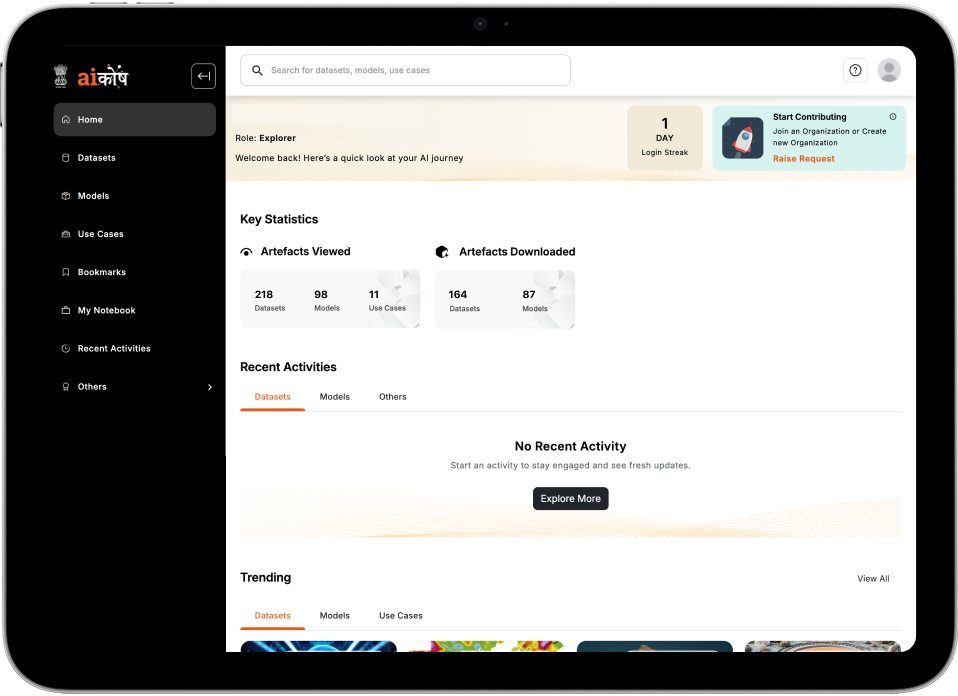
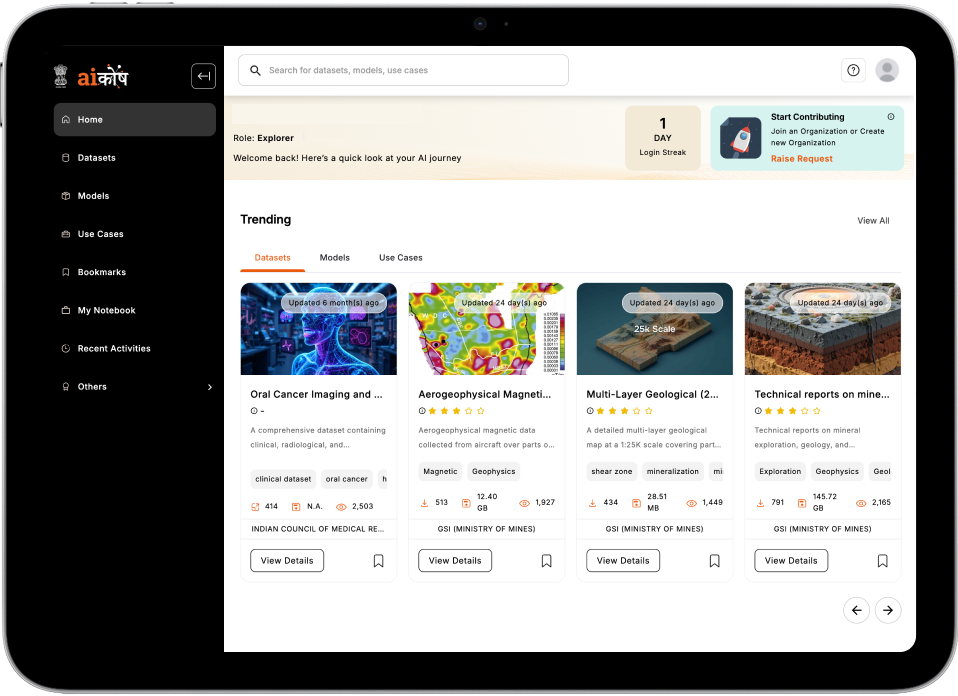
IndiaAI wanted a single national repository consolidating datasets from government and private contributors. The platform had to provide affordable, authentic, and privacy-compliant data. It also needed built-in tools for experimentation and model training, with the ability to scale and onboard more ministries, organizations, and contributors. Unthinkable developed this solution.
Key requirements were:
Conduct an initial discovery phase to identify fragmented datasets, stakeholders, and integration requirements.
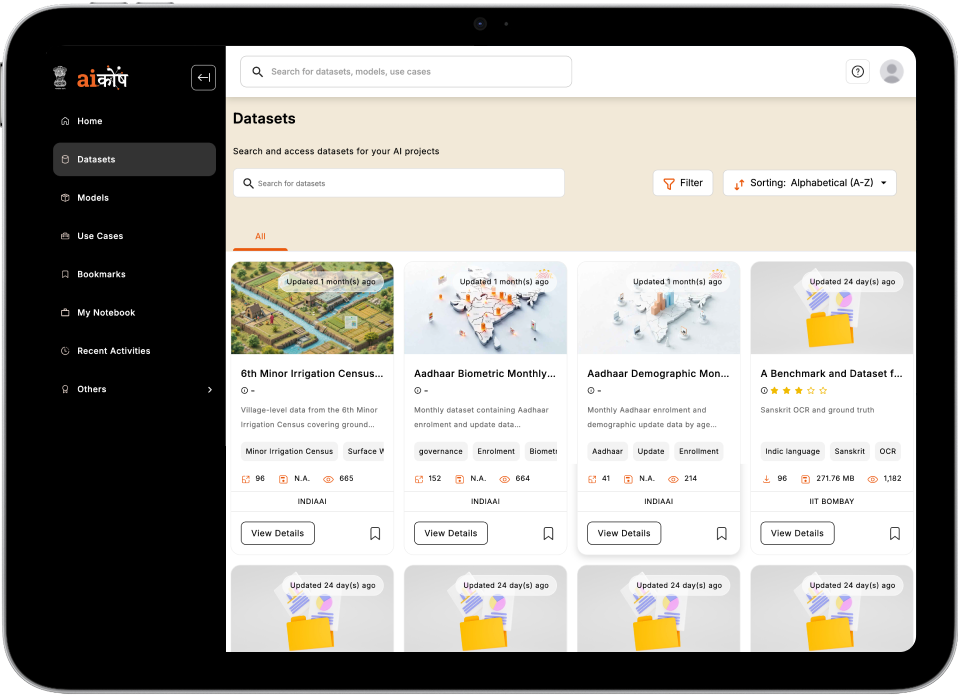
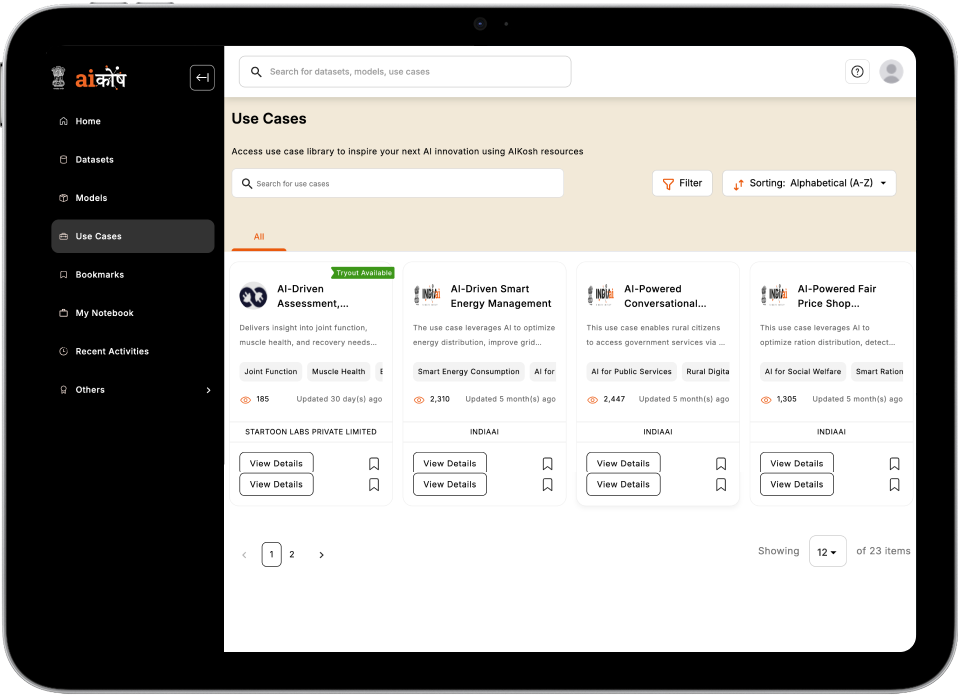
Aggregate datasets, models, and resources into a centralized and searchable repository.
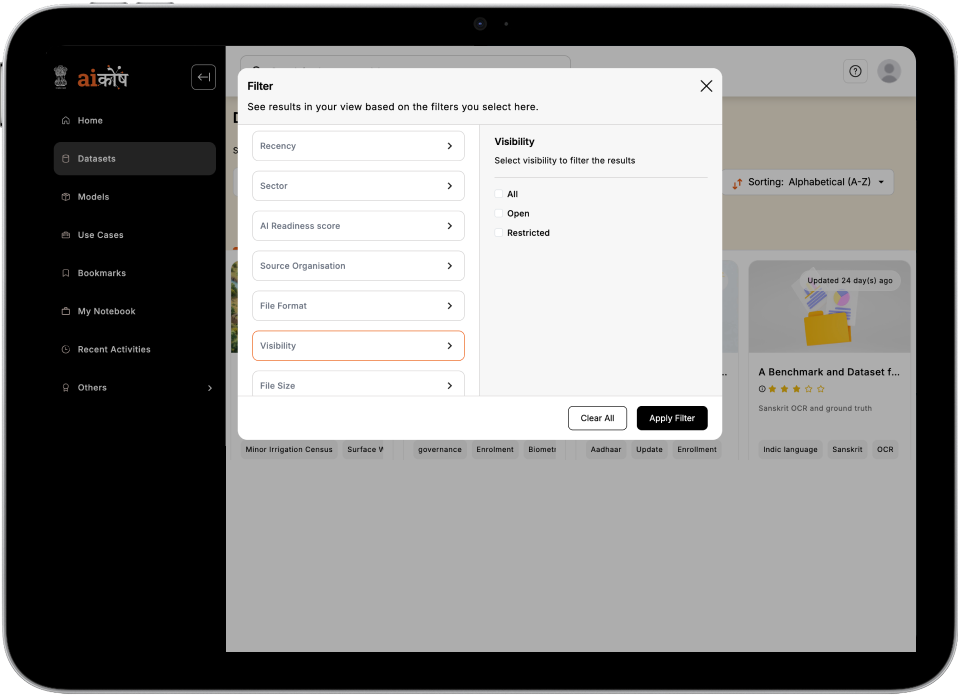
Implement a multi-level validation and approval process to publish only verified datasets.
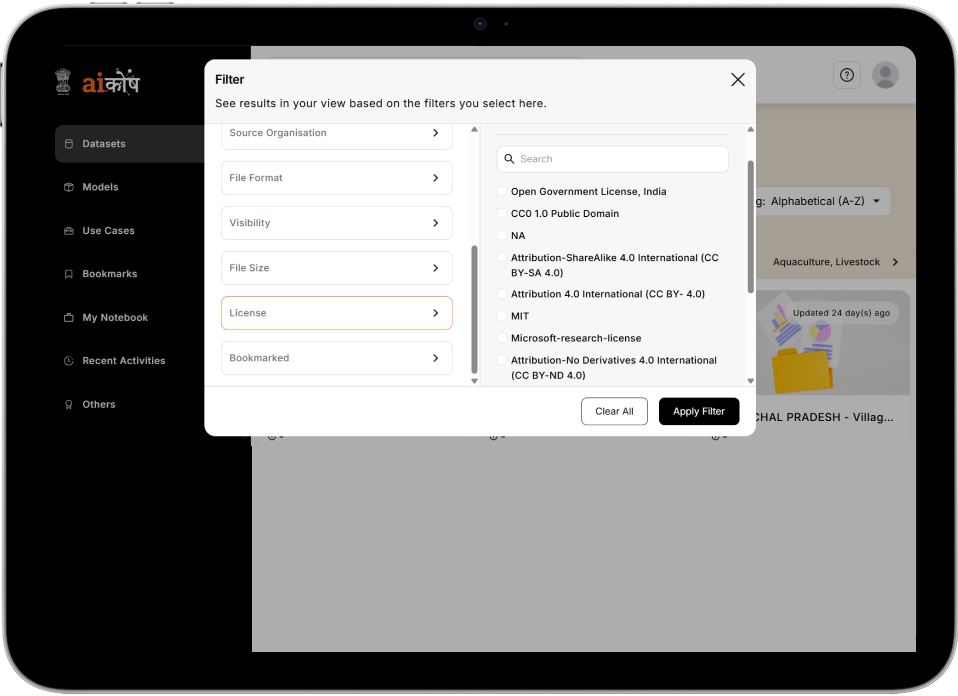
Define clear licensing terms for each dataset to ensure transparent usage and sharing rights.
Enable contributors to control dataset access, including open download, request-based access, or private use.
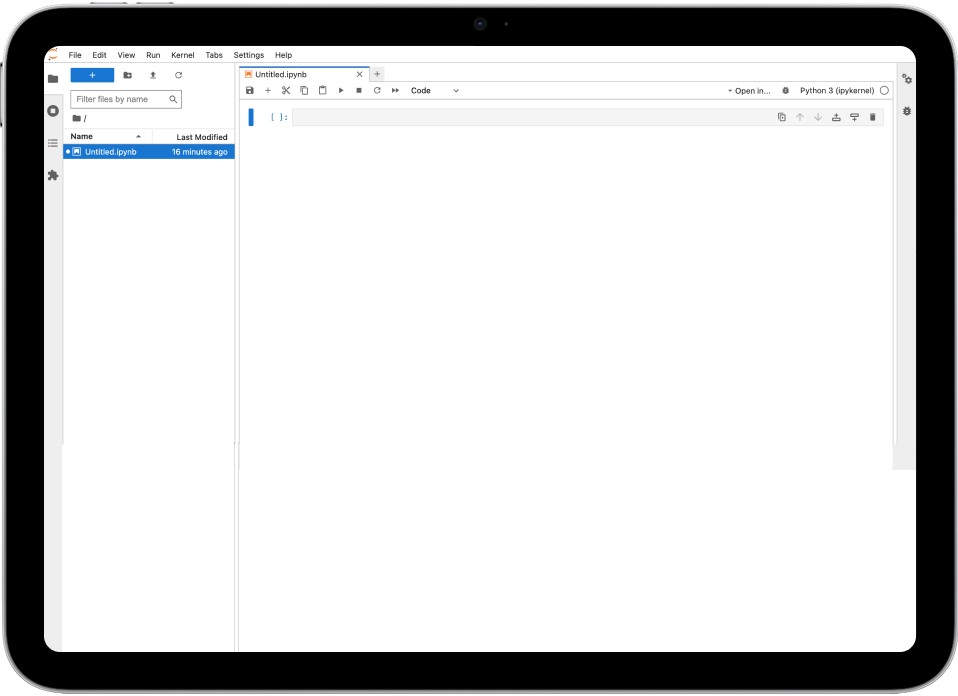
Provide a GPU-enabled sandbox environment to test datasets and train AI models directly on the platform.